在前面的學習中,我們了解了神經網絡的基本結構和卷積神經網絡(CNN)的應用。今天,我們將探討深度學習中的另一個重要領域——生成式模型(Generative Models)。生成式模型可以學習數據的分佈,並能夠生成與原始數據相似的新數據。在AI換臉技術中,生成式模型扮演了關鍵角色,特別是自編碼器(Autoencoder)和變分自編碼器(Variational Autoencoder, VAE)。
生成式模型旨在學習數據的概率分佈𝑝(𝑥),使得模型可以生成新的、與訓練數據相似的數據點。與之相對的是判別式模型(Discriminative Models),後者關注於學習輸入數據與標籤之間的關係𝑝(𝑦∣𝑥)。
自編碼器是一種無監督學習模型,旨在學習數據的高效表示(編碼)。它由兩部分組成:
編碼器(Encoder):將輸入數據 𝑥映射到隱含表示𝑧。
解碼器(Decoder):將隱含表示𝑧重建為輸出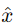 。
。
輸入層:接收原始數據𝑥。
隱藏層(瓶頸層):隱含表示𝑧,通常維度低於輸入維度,起到降維的作用。
輸出層:重建輸出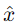 ,希望與輸入𝑥盡可能相似。
,希望與輸入𝑥盡可能相似。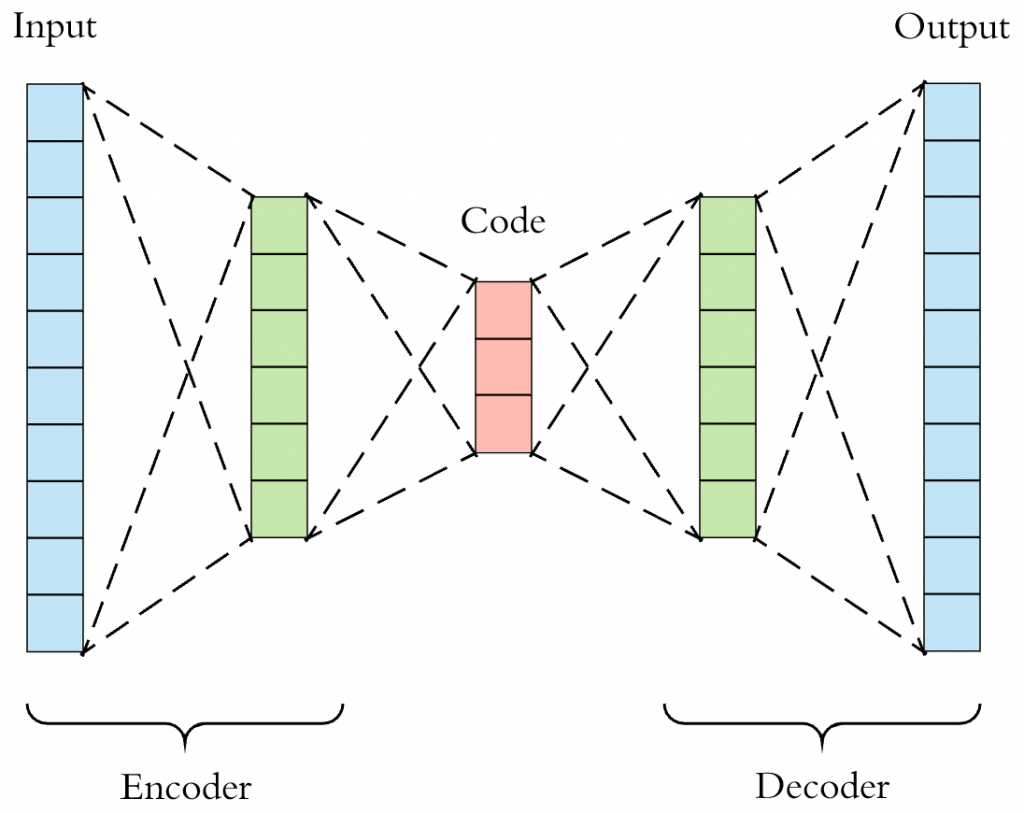
圖1 自編碼器的編碼器和解碼器對稱結構。
自編碼器的訓練目標是最小化輸入𝑥和重建輸出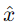 之間的差異。常用的損失函數為均方誤差(MSE):
之間的差異。常用的損失函數為均方誤差(MSE):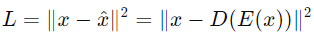
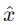
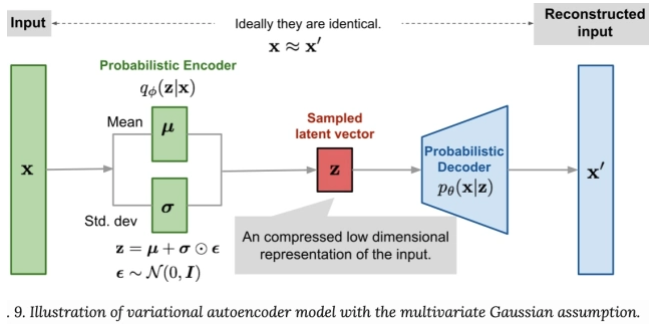
傳統自編碼器只能學習一種映射關係,缺乏對數據生成過程的建模。VAE引入了概率模型的思想,能夠顯式地學習數據的分佈,從而更有效地生成新數據。
VAE假設數據的生成過程是通過一個潛在變量𝑧產生的,並引入了編碼器和解碼器的概率模型:
編碼器(推斷模型):𝑞𝜙(𝑧∣𝑥),近似後驗分佈。
解碼器(生成模型):𝑝𝜃(𝑥∣𝑧),生成數據的概率分佈。
VAE的損失函數是基於證據下界(ELBO),旨在最大化數據的邊緣似然: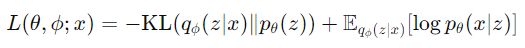
為了能夠通過梯度下降優化,VAE使用了重參數化技巧,將隨機變量𝑧的採樣過程轉換為可導的操作: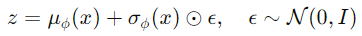
| 特性 | 自編碼器(AE) | 變分自編碼器(VAE) |
|---|---|---|
| 編碼器輸出 | 固定向量𝑧 | 均值和標準差𝜇,𝜎 |
| 解碼器輸入 | 固定向量𝑧 | 隨機採樣的𝑧 |
| 生成能力 | 有限(不擅長生成新數據) | 強(可生成新數據) |
| 損失函數 | 重建誤差(如MSE) | 重建誤差 + KL散度 |
| 潛在空間 | 不一定連續 | 連續且有結構 |
雖然今天的重點是自編碼器和VAE,但在我們第一天有提過,生成對抗網絡(GAN) 也是非常重要的一種模型。GAN通過生成器和判別器的對抗訓練,能夠生成極為逼真的圖像。在後續的學習中,我們將深入探討GAN及其在換臉技術中的應用。
今天我們學習了生成式模型的基本概念,深入了解了自編碼器和變分自編碼器的原理、結構和應用。自編碼器通過學習數據的高效表示,實現了數據的降維和重建;而VAE進一步引入了概率模型,能夠生成新的數據樣本,為換臉技術提供了強大的工具。在未來的課程中,我們將繼續探討其他生成式模型,如GAN,並學習如何將這些模型應用於實際的換臉項目中。
那我們明天再見了~掰掰~~

